“ASR Status Report 2016-12-26”版本间的差异
来自cslt Wiki
Wangyanqing(讨论 | 贡献) |
|||
| (4位用户的10个中间修订版本未显示) | |||
| 第10行: | 第10行: | ||
|Jingyi Lin | |Jingyi Lin | ||
|| | || | ||
| − | * | + | * Learn and make Dr.Wang's personal web page. |
| + | * Prepare for the CSLT's Annual Meeting. | ||
|| | || | ||
| − | * | + | * Finish Dr.Wang's personal web page. |
| + | * Take photos for menmbers in CSLT. | ||
|- | |- | ||
| 第26行: | 第28行: | ||
* screenshot: | * screenshot: | ||
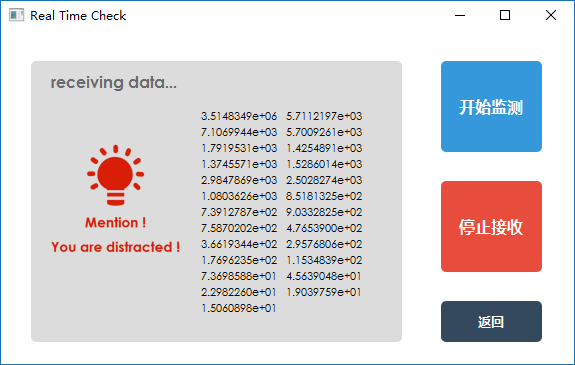
** [[媒体文件:dataSender.png|data sender]] | ** [[媒体文件:dataSender.png|data sender]] | ||
| − | **[[媒体文件: | + | **[[媒体文件:dataAnalyser.png|data analyzer]] |
|| | || | ||
* write a document on the program | * write a document on the program | ||
| 第37行: | 第39行: | ||
|Hang Luo | |Hang Luo | ||
|| | || | ||
| − | * | + | * Run joint training and write systemic script and documents |
|| | || | ||
| − | * | + | * Finish joint training documents |
| + | * Conclude joint training experiments result | ||
| + | * Make a review on mixlingual | ||
|- | |- | ||
| 第59行: | 第63行: | ||
|Yixiang Chen | |Yixiang Chen | ||
|| | || | ||
| − | * | + | * Prepare the input of speech data (trick of block segmentation) |
| + | * Complete the init version on max-margin SRE. | ||
| + | * Write TRP-20160012 "基于Kaldi i-vector的说话人识别系统使用说明"'''[delivery]'''. | ||
|| | || | ||
| − | * | + | * Prepare the thesis proposal. |
| + | * Integrate CNN + max-margin. | ||
|- | |- | ||
| 第68行: | 第75行: | ||
|Lantian Li | |Lantian Li | ||
|| | || | ||
| − | * | + | * Deep speaker embedding |
| + | ** Prepare two datasets and make the i-vector baselines. | ||
| + | * Write TRP-20160012 "基于Kaldi i-vector的说话人识别系统使用说明"'''[delivery]'''. | ||
| + | * Write book of robustness SRE. | ||
| + | * Wechat open account. | ||
|| | || | ||
| − | * | + | * Deep speaker embedding. |
| + | * Write book. | ||
| + | * Replay detection on INTERSPEECH chanllenge. | ||
|- | |- | ||
| 第78行: | 第91行: | ||
|| | || | ||
* TRP of "How to Config Kaldi nnet3 (in Chinese)", not finished yet; | * TRP of "How to Config Kaldi nnet3 (in Chinese)", not finished yet; | ||
| − | * outline of TRP for "Multi-task Recurrent Model for True Multilingual Speech Recognition". | + | * outline of TRP for "Multi-task Recurrent Model for True Multilingual Speech Recognition"; |
| + | * Generative models, part of Chapter Deep Learning. | ||
|| | || | ||
| − | * Finish the above | + | * Finish the above 3 writings. |
|- | |- | ||
2017年1月4日 (三) 07:28的最后版本
| Date | People | Last Week | This Week |
|---|---|---|---|
| 2016.12.26
|
Jingyi Lin |
|
|
| Yanqing Wang |
|
| |
| Hang Luo |
|
| |
| Ying Shi |
|
| |
| Yixiang Chen |
|
| |
| Lantian Li |
|
| |
| Zhiyuan Tang |
|
|
{kind=link}
{kind=link}
| Date | People | Last Week | This Week |
|---|---|---|---|
| 2016.12.19
|
Jingyi Lin |
|
|
| Yanqing Wang |
|
| |
| Hang Luo |
|
| |
| Ying Shi |
|
| |
| Yixiang Chen |
|
| |
| Lantian Li |
|
| |
| Zhiyuan Tang |
|
|
{kind=link}
{kind=link}